
PhD student: Holger Severin Bovbjerg
Supervisors: Zheng-Hua Tan, Jan Østergaard and Jesper Jensen

Recent development in the field of machine learning has made computers able to solve a range of complex tasks by leveraging the vast amount of data that is available today.
In the future, machine learning models are expected to be able to assist humans in day-to-day life and even extend human ability.
Hearing assistive (HA) devices such as hearing aids or headphones are examples of technology where development of new machine learning methods are seen as a key component for advancing the current state-of-the-art in order to improve the quality of life for people using this technology.
While machine learning holds promises for future advanced HA technology, a number of limitations to the current methods have to be dealt with.
One problem of current machine learning methods is the need for large amounts of data with human annotated labels to achieve good performance.
As data labelling is labor-intensive, obtaining large amounts of labelled data is costly, whereas unlabelled data is generally available in abundance.
In this regard, self-supervised learning methods have shown to be able to learn good representations of data without the need for labels.
This is done by initially training the model to solve a self-supervised pretext task, wherein the supervisory signals are extracted from the data itself.
Besides mitigating the need for data labels, self-supervised learning methods have also shown to outperform supervised methods on multiple tasks and be more robust to acoustic noise.
As a result, many experts have named self-supervised learning as a key element in the development of future machine learning technology.
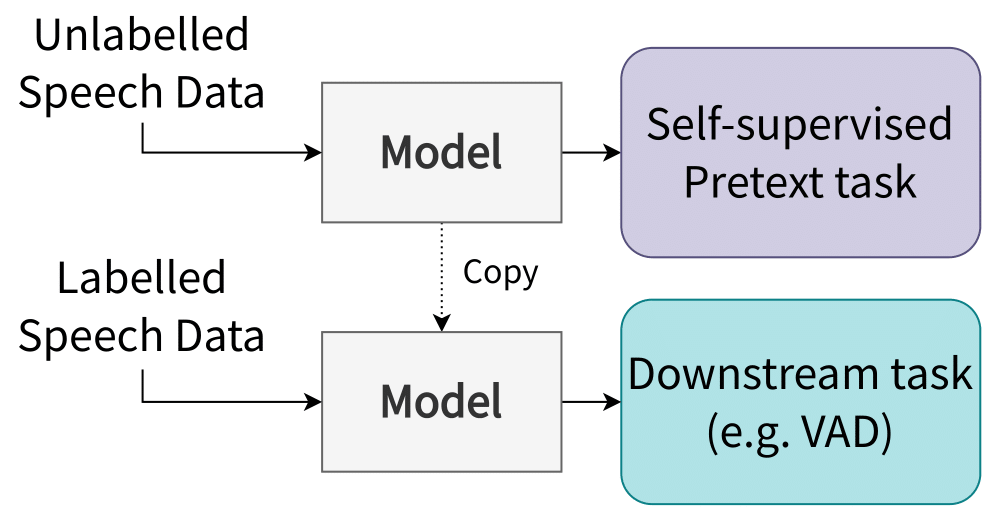
In this project, the use of self-supervised learning methods for speech source detection in HA devices is studied.
The project aims at identifying how self-supervised learning can be used to improve upon two existing technologies known as Voice Activity Detection (VAD) and Direction of Arrival Estimation (DoAE).
The former can, e.g., be used for gating the input for a speech processing system such that only speech is sent through, and the latter to determine the direction of a sound source, e.g., in order to focus the directivity of a microphone array in the direction of the speaker.
Both technologies are important components in improving the quality of speech for future HA devices.
The main contribution of this project will be an investigation of the use of self-supervised learning for VAD and DoAE for improved performance in diverse real-world conditions with background noise.